As you can probably tell by my other articles (for example here, here and here), I am a big fan of GARCH models. Forecasting conditional variance is arguably the best we can get in predicting stock returns out of themselves.
Still, the GARCH family is no silver bullet that suddenly makes you a stock wizard. Countless variations imply that there is no single best approach to handle conditional variance.
Today, let us look at one interesting variant of GARCH - namely, Varying Coefficient GARCH. If you are in a hurry, you can find the Jupyter notebook corresponding to this article here.
Drawbacks of traditional GARCH
First, we’ll quickly go through some limitations of the standard GARCH model. Although we have discussed them before, it’s always good to refresh important aspects of our models.
For simplicity, we will only go through GARCH(1,1). The generalized version just uses an arbitrary number of lags for both squared observations and variance. Also, we assume a constant mean of zero.
With that in mind, GARCH(1,1) follows the following equations: \[
\begin{gathered}
y_t \sim \mathcal{N}\left(0, \sigma_t^2\right) \\
\sigma_t^2=\omega+\alpha y_{t-1}^2+\beta \sigma_{t-1}^2 \\
\omega>0 \\
0<\alpha+\beta<1
\end{gathered}
\] From these, we can derive two important issues:
The linear assumption of GARCH
GARCH makes the relatively light assumption of variance being a linear combination of past data. On the one hand, this goes very well with Occam’s razor. Simpler models are very often more robust.
One observation I often make when experimenting with more flexible GARCH models is overfitting. Consider a very bad probabilistic model for some data. If you allow variance to be very flexible, you just need to make that variance very large. Then, all of your training observations will still achieve a reasonably well likelihood or model fit.
Thus, the linearity assumption guarantees a sensible amount of model regularization. On the other hand, this might nevertheless be too restrictive when linearity is clearly not present in the data.
The Gaussian assumption
Probably the most common assumption of all foundational statistical and econometrical models. In standard GARCH, we presume Gaussian observations as well. The only difference to your standard time-series models is that we are predicting variance, not the mean.
As mentioned countless times before, real-world data is almost never Gaussian. This is particularly the case for stock market returns, where GARCH is probably used the most. Hence, a fundamental assumption of our model stands in conflict with real-world observations.
In practice, the Gaussian distribution is often replaced by something more flexible. Examples include the location-scale Student-t distribution or the Generalized Beta distribution.
Today, we are considering the linearity issue of GARCH. For a possible treatment of the Gaussian issue, you can also take a look at this article of mine.
Motivation for Varying Coefficient GARCH
As already mentioned, the linearity assumption can be limiting. The obvious fix would be to just use some non-linear alternative and call it a day. However, there are two issues with that. Let us start with the bigger one first:
It is difficult to prove stability of non-linear models. Depending on our particular model, it can be tricky, if not impossible to ensure that it is well behaved. At worst, we could see the forecast going completely bonkers over time.
With a plain linear model and some fundamental theory, it is straightforward to ensure that this doesn’t happen. Using an arbitrary model, though, this advantage can easily vanish.
The second issue is that standard non-linear models are hard to interpret. Consider again the standard GARCH setup: We can easily reason about the effect of each ‘factor’ in our model. Without further ado, we could also include additional factors like company sector, etc. in our model.
Obviously, this is not possible with an arbitrary, non-linear alternative anymore. Thus, considering both the above issues, a varying coefficient model becomes quite attractive.
Varying coefficient models
The straightforward rationale of varying coefficient models is the following: If fixed parameters are restrictive, why not just make them dynamic?
And indeed, this is what varying coefficient models are all about. Our primary goal is to move from static coefficient to ones that are dynamic given different inputs.
In a linear regression model, this could look as follows: \[
y=X \beta(X)
\] The coefficients are simply a function of the inputs. Thus, each input can have a unique set of linear model parameters. This allows us to model non-linear functions in a - locally - linear fashion.
For standard regression models there exists a lot of previous research dating back into the nineties. Nowadays, we also see some modern approaches to varying coefficient models.
One example is this fairly recent paper which uses neural networks to model varying coefficients on a large scale. There, the approach is used for image classification. The findings are quite impressive - the model is able to highlight reasonable image sections that are most relevant for the model output.
Obviously, there also exists previous work on varying coefficient GARCH already, see for example
To keep things easy for now, we’ll use a fairly simplistic variant. From there, you can try different variations yourself.
Varying Coefficient GARCH
Let us re-state the standard GARCH(1,1) equations from before: \[
\begin{gathered}
y_t \sim \mathcal{N}\left(0, \sigma_t^2\right) \\
\sigma_t^2=\omega+\alpha y_{t-1}^2+\beta \sigma_{t-1}^2 \\
\omega>0 \\
0<\alpha+\beta<1
\end{gathered}
\] An alternative with varying coefficients then makes the coefficients a function of some variables of interest: \[
\begin{gathered}
y_t \sim \mathcal{N}\left(0, \sigma_t^2\right) \\
\sigma_t^2=\omega+\alpha_t y_{t-1}^2+\beta_t \sigma_{t-1}^2 \\
\alpha_t=\phi\left(y_{t-1}, \sigma_{t-1}\right) \\
\beta_t=\psi\left(y_{t-1}, \sigma_{t-1}\right)
\end{gathered}
\] Let us, again for simplicity, use a feedforward neural network to model the varying coefficients:
Structural diagram of a varying coefficient GARCH model. The coefficients vary as a Neural Network function of past realizations and past standard deviation.
Now, we can take advantage of linearity in the varying coefficients and ensure stationarity via \[
0<\alpha_t+\beta_t<1
\] for all \(t\)
For static coefficient GARCH, it is relatively easy to ensure this stationarity condition. Just use one of the popular optimization packages and enter the respective linear constraint.
In the varying coefficient case this might, at first sight, not be as obvious. Libraries for neural networks don’t allow any constraints on the network output out-of-box. Thus, we need to build a solution to this problem ourselves.
For GARCH(1,1), this is actually very simple. We only need to find a transformation of our network output, that ensures stationarity. In fact, we can simply do the following: \[
\begin{aligned}
&\begin{gathered}
\alpha_t=\sigma\left(\tilde{\alpha}_t\right) \\
\beta_t=\left(1-\sigma\left(\tilde{\alpha}_t\right)\right) \cdot \sigma\left(\tilde{\beta}_t\right)
\end{gathered}\\
&\sigma(x)=\frac{1}{1+e^{-x}}
\end{aligned}
\] By playing around with the sigmoid function, we can quickly find a suitable transformation. For arbitrary GARCH order, this can be more of a hassle, so we won’t consider this case here.
Some rationale behind the model
You might wonder why we don’t make the parameters dependent on squared past realizations and past variance. For the latter, it shouldn’t make that much of a difference if we used variance instead of standard deviation.
For past observations, though, there is a clear advantage: Negative and positive realizations of the time-series can affect future variance differently. In the stock market example, large negative returns are likely to cause greater variance in subsequent periods. This is, for example, the philosophy behind the TGARCH model.
As for the neural network, we could also use other popular function approximators. This includes Regression Splines or higher order polynomials. Given their still undefeated popularity, I decided that neural networks would be the most interesting choice.
A quick demonstration of varying coefficient GARCH
In other GARCH articles, I have primarily used Python for the implementation. Today, let us use Julia for fun and education. Personally, I find the language much more efficient for some quick experiments. On the other hand, deployment is less of a pleasure if you need to manage the JIT overhead.
We begin with the usual data loading process. Here, I used 5 years of DAX data from yahoo finance and calculated the log-returns of the adjusted close price. The final 100 observations are kept in a holdout set:
Next, we create our varying coefficient GARCH. As Julia is more or less a functional language, there aren’t any classes, unlike Python.
Also, we do not store the latent state of our model (= the conditional variance) over time. This is due to the fact that Zygote, one of Julia’s AutoDiff libraries, doesn’t allow mutating arrays. Rather, we recursively call the respective function and pass the current state to the next function call.
(Technically, it is possible to store intermediate states in a Zygote.Buffer. Let us here use the functional variant anyway for educational purposes.)
usingFlux, Distributionsstruct VarCoeffGARCH constant::Vector{Float32} net::Chain x0::Vector{Float32}endFlux.@functor VarCoeffGARCHVarCoeffGARCH(net::Chain) =VarCoeffGARCH([-9], net, [0.0])functiongarch_mean_ll(m::VarCoeffGARCH, y::Vector{Float32})::Float32 sigmas, _ =garch_forward(m,y) conditional_dists =Normal.(0, sigmas)returnmean(logpdf.(conditional_dists, y))end#Use functional implementation to calculate conditional stddev.#Then, we don't need to store stddev_t to calculate stddev_t+1#and thus avoid mutation, which doesn't work with Zygote#(could use Zygote.Buffer, but it's often discouraged)functiongarch_forward(m::VarCoeffGARCH, y::Vector{Float32}) sigma_1, params_1 =m(m.x0[1], sqrt(softplus(m.constant[1]))) sigma_rec, params_rec =garch_forward_recurse(m, sigma_1, y, 1) sigmas_result =vcat(sigma_1, sigma_rec) params_result =hcat(params_1, params_rec)return sigmas_result, params_resultendfunctiongarch_forward_recurse(m::VarCoeffGARCH, sigma_tm1::Float32, y::Vector{Float32}, t::Int64) sigma_t, params_t =m(y[t], sigma_tm1)if t==length(y)-1return sigma_t, params_tend sigma_rec, params_rec =garch_forward_recurse(m, sigma_t, y, t+1) sigmas_result =vcat(sigma_t, sigma_rec) params_result =hcat(params_t, params_rec)return sigmas_result, params_resultendfunction (m::VarCoeffGARCH)(y::Float32, sigma::Float32) input_vec =vcat(y, sigma) params = m.net(input_vec) params_stable =get_garch_stable_params(params) #to ensure stationarity of the resulting GARCH processreturnsqrt(softplus(m.constant[1]) +sum(input_vec.^2.* params_stable)), params_stableend#transform both parameters to be >0 each and their sum to be <1get_garch_stable_params(x::Vector{Float32}) =vcat(σ(x[1]), (1-σ(x[1]))*σ(x[2]))
get_garch_stable_params (generic function with 1 method)
Next, we create and train our varying coefficient GARCH model. Notice that I used a rather tiny architecture for the respective neural network. This hopefully counters the risk of overfitting to some extent.
If we were more engaged, we could experiment with different architectures. Here, however, this is left as an exercise to the reader.
Notice that we get the gradients via AutoDiff from Zygote. Another popular approach for GARCH models is to use black-box gradients via finite differences. Given that our neural network could easily have many more parameters, this would quickly become infeasible.
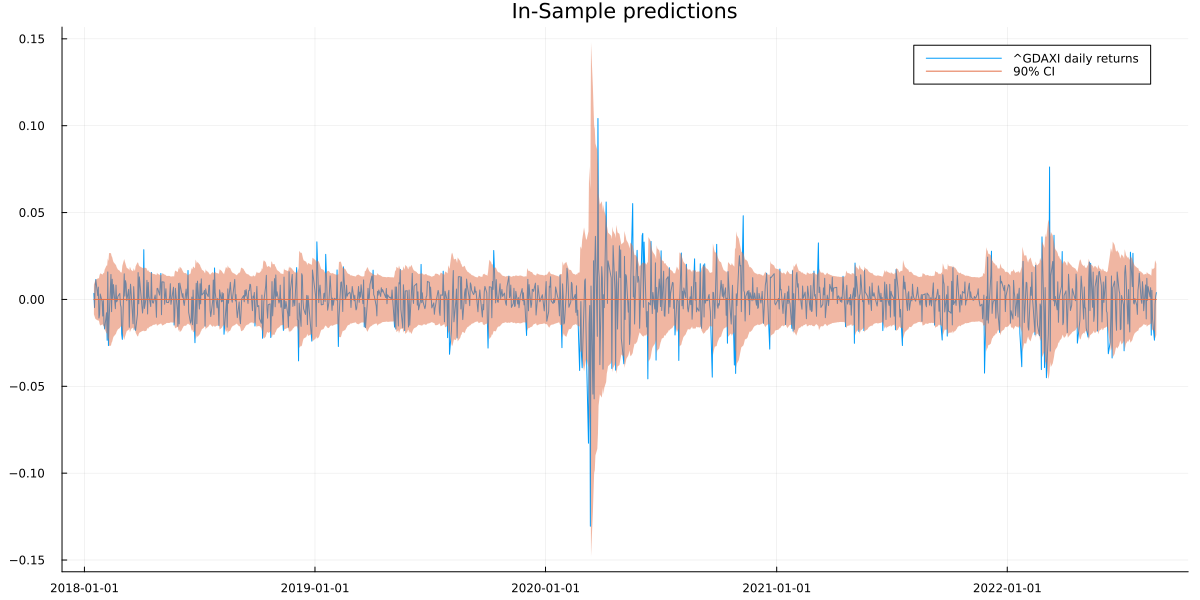
After model fitting, we can plot the in-sample predictions to check if everything went well:
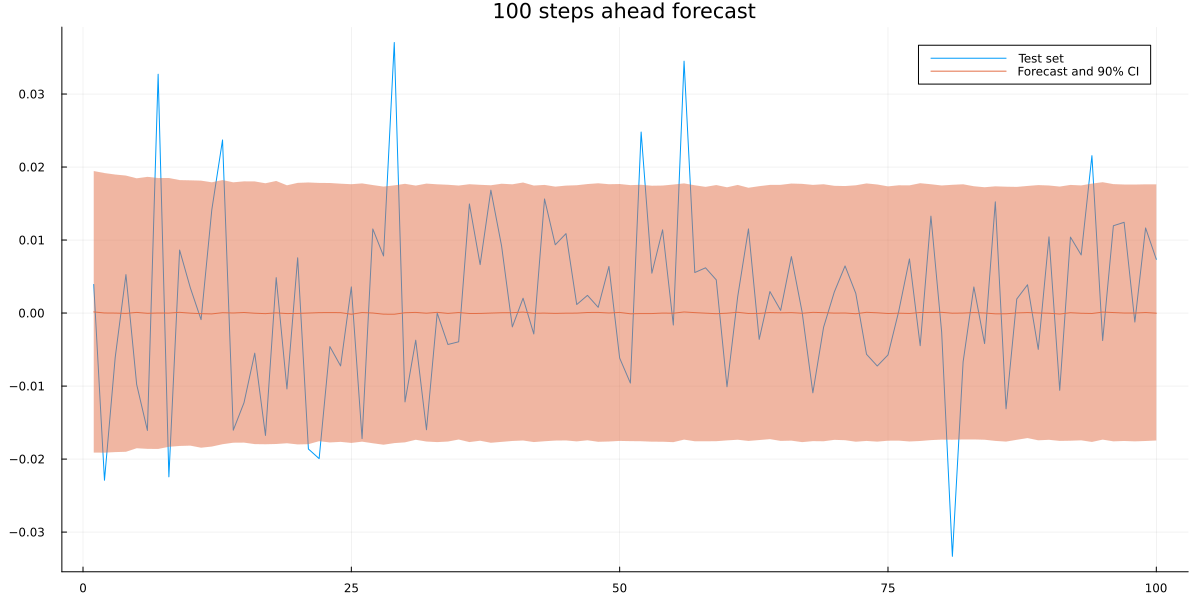
This looks like a reasonable GARCH prediction for in-sample data. To see if it also works out-of-sample, we generate a forecast via MC-sampling. This is necessary as we cannot integrate out the probabilistic forecast at \(t\) for \(t+1\) analytically.
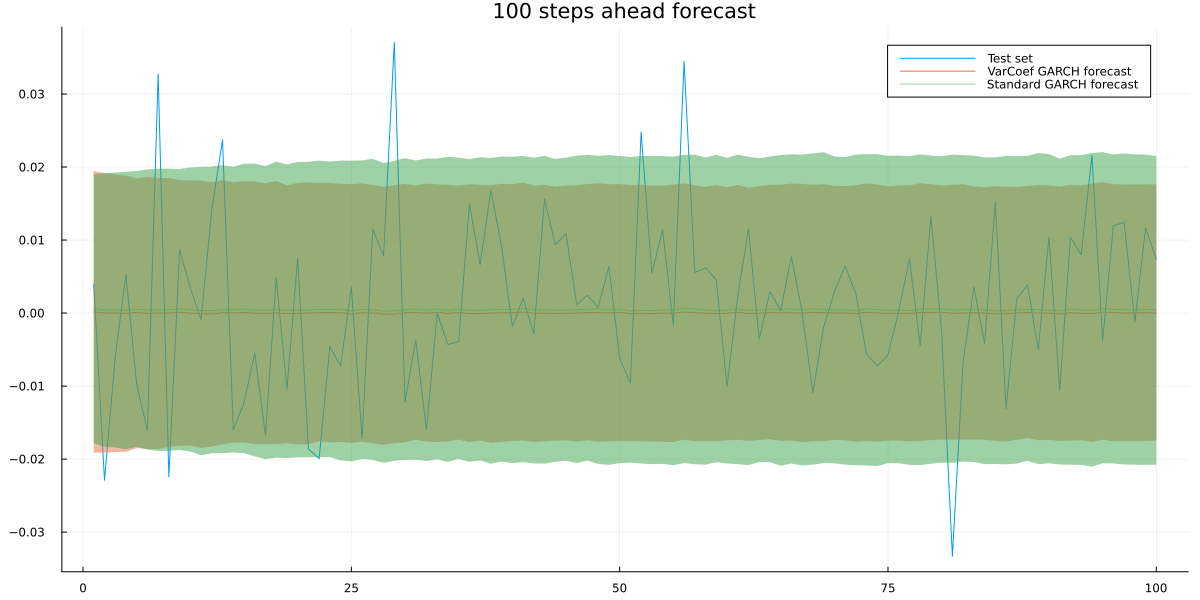
Again, a reasonably looking plot. Since we also want to check if we built anything useful, let us also compare to a standard GARCH(1,1) forecast. We need to integrate out numerically once more:
The standard GARCH model produces a larger forecast interval. To make both models comparable quantitatively, we use the average out-of-sample log-likelihoods:
usingKernelDensityvar_coef_ll =mean([log(pdf(kde(y_forecast_sample[t,:]),test[t])) for t in1:100])standard_ll =mean([log(pdf(kde(garch_forecast_sample[t,:]),test[t])) for t in1:100])println(var_coef_ll)println(standard_ll)
3.006017233022985
3.0003596946242705
Our model has a slightly better out-of-sample log-likelihood. Obviously, we could likely improve this with different architectures and/or a higher GARCH model order. Just try not to overfit!
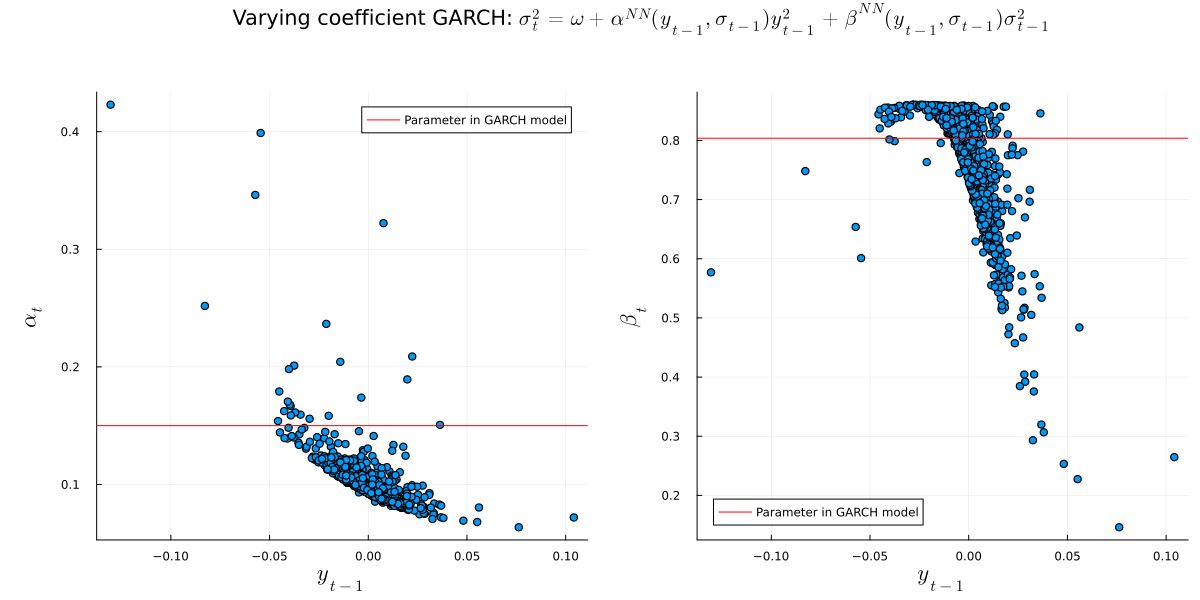
Finally, we can take a look at the behaviour of the varying coefficients. One interesting view is past in-sample observations against each coefficient. For comparison, I also added the fixed coefficient from standard GARCH:
Interestingly, both varying coefficients are in the same ballpark as standard GARCH. This adds some confidence that we are on the right track.
Nevertheless, as mentioned above, there is possibly still a lot of room for improvement.
Conclusion
Now, where do we go from here? To put it bluntly, we have yet another GARCH variation that promises to fix one limitation of standard GARCH. With a little sophistication, we get a model that is flexible and fairly transparent at the same time.
Now we could, for example, easily introduce external factors to our model. The current state of the general economy or the company’s sector are likely to influence return volatility.
With our varying coefficient GARCH, we can account for such effects. At the same time, it is possible to validate the predicted effect of each feature.
The biggest advantage in my opinion is, however, that we don’t have to worry about stationarity. If we restrict our model to always yield valid GARCH coefficients, there is no risk of exploding forecasts.
This makes this model quite powerful, yet fairly simple to handle. If you have any questions about it, please let me know.
References
[1] Bollerslev, Tim. Modelling the coherence in short-run nominal exchange rates: a multivariate generalized ARCH model. The review of economics and statistics, 1990, p. 498-505.
[2] Donfack, Morvan Nongni; Dufays, Arnaud. Modeling time-varying parameters using artificial neural networks: a GARCH illustration. Studies in Nonlinear Dynamics & Econometrics, 2021, p. 311-343.
[3] Hastie, Trevor; Tishbirani, Robert. Varying coefficient models. Journal of the Royal Statistical Society: Series B (Methodological), 1993, p. 757-779.